正则表达式
正则表达式
正则表达式,可以简单理解为快速匹配字符,当然啊它不仅能匹配,还可以利用编程(Python、PHP等语言)函数 删除、修改等操作。
正则表达式不仅仅在网络安全领域很常用,在其他领域也尝尝能见到它的身影,如Python爬虫利用正则表达式来提取标签,PHP利用正则表达式来过滤非法请求等
表示字符
| 字符 | 描述 |
|---|---|
| . | 匹配任意一个字符 |
| [] | 匹配范围里面的字符 |
| \d | 匹配0-9数字 |
| \D | 匹配非数字 |
| \s | 匹配空白字符 空格 tab键 |
| \S | 匹配非空白字符 |
| \w | 匹配单词字符 a-z A-Z 0-9(包括下划线_) |
| \W | 匹配非单词字符 |
数量表示
| 字符 | 描述 |
|---|---|
| * | 匹配前一个字符出现的次数,可以表示无数次 次数 可有可无 |
| + | 匹配前一个字符出现的1次或无数次,至少有一次 |
| ? | 配前一个字符出现的次数,可有可无 |
| {x} | 表示前面的字符出现x次 |
| {x,} | 匹配前一个字符最少出现x次 |
| {x,m} | 匹配前一个字符出现次数为x到m次 |
位置表示
| 字符 | 描述 |
|---|---|
| ^ | 表示字符串开头 |
| $ | 表示字符串结尾 |
| \b | 表示一个单词边界 |
| \B | 匹配非单词边界 |
贪婪模式:
尽可能匹配多的信息
| 字符 | 描述 |
|---|---|
| .* | 贪婪模式 |
| .*? | 取消贪婪 |
PHP中的 preg_match 函数
Python中的 寻找所有匹配 findall
在我们急于在种众多信息中需找某些特定的信息时候,正则表达式就发挥了很大的作用,简单,方便,快捷的特性就展现出来了
例如
Kali查用户名
比如我们要查找Kali中的所有用户的用户名
可以使用
1 | |
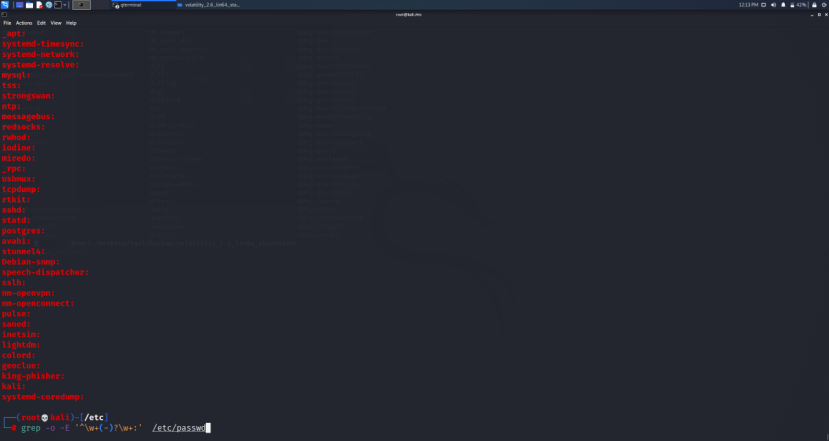
-o: 只显示匹配字符-E: 使用正则匹配^\w+:以单词字符 a-z A-Z 0-9(包括下划线_)开头的最少一次(-)?:有的用户名中间有一个横线 -,?为可有可无\w+::横线- 后边有的还是会有字符的,最少出现一次,末尾规定了冒号:
手机号
1 | |
1 | |
1代表开头的1[3-9]匹配第二个数字\d{9}匹配后边的9个数字\d匹配数字{9}表示 \d 匹配的值要出现 9 次
邮箱
1 | |
1 | |
这个正则表达式用于匹配电子邮件地址。下面是对这个正则表达式的详细解释:
\w+:匹配一个或多个字母、数字或下划线字符。这部分对应电子邮件地址的用户名部分。([-+.]\w+)*:这是一个可选的组,匹配零次或多次以下模式。[-+.]:匹配连字符、加号或点号。这些字符可以在电子邮件用户名中出现。\w+:再次匹配一个或多个字母、数字或下划线字符。
这个组允许用户名中包含这些特殊字符,但这部分是可选的。
@:匹配电子邮件地址中的 “**@** ” 符号,这是必需的。\w+:匹配电子邮件地址中的 域名 部分的 第一个单词 ,同样是一个或多个字母、数字或下划线字符。([-.]\w+)*:这是一个可选的组,匹配零次或多次以下模式。[-.]:匹配连字符或点号。这些字符可以出现在域名中。\w+:匹配一个或多个字母、数字或下划线字符。
这个组允许域名中包含这些特殊字符,并且可以出现多次,但这部分是可选的。
\.:匹配电子邮件地址中的点号 (.),用于分隔域名和顶级域。\w+:匹配电子邮件地址的 顶级域,这是一个或多个字母、数字或下划线字符。([-.]\w+)*:与前面的([-.]\w+)*相同,但这次它匹配顶级域名中可能出现的额外部分,如 “.co.uk“ 中的 “.uk“。
总的来说,这个正则表达式匹配一个基础的电子邮件地址格式,同时允许在用户名和域名中包含一些特殊字符,并且可以匹配带有多个部分的顶级域名。